Code
library(data.table)
library(DBI)
library(ggplot2)
library(dplyr)
library(DBI)
library(gt)
library(tidyr)
library(textutils)
require(dbplyr)This project shows my ability to handle a new data set and extract relevant and useful information in a systematic and clean manner. It is entirely in German. First, I give the final summary text of my findings and then I will guide through the steps of working with the data in detail.
Blickt man auf Geschäftsführer:innen im deutschen Handelsregister, fällt auf, dass mit großem Abstand ein Name am häufigsten fällt: Katja Gogalla. Sie allein schafft es auf über 4900 Einträge. Gogalla arbeitet als Account Manager für die Blitzstart Holding GmbH und gründet dort professionell Vorratsgesellschaften. Das sind Firmen, die keine Geschäftstätigkeiten aufnehmen und einfach an Kund:innen weiterverkauft werden können. Dieses Geschäftsmodell praktiziert sie seit 2004 und steigert kontinuierlich die monatlichen Eintragungen auf ihren Namen im gesamten Bundesgebiet. Waren es in den ersten Jahren ihrer Tätigkeit immerhin ca. 20 Firmen pro Monat so stieg diese Zahl im Jahr 2017 auf über 80 Firmen pro Monat. Am 19.01.2016 wurde Gogalla auf einen Schlag als Geschäftsführerin für 34 Firmen eingetragen – ein persönlicher Rekord. Die Analyse zeigt, dass Blitzstart die Firmen mit Namen wie “Blitz S18-202 GmbH” durchschnittlich 108 Tage (84 Tage im Median) behält, bevor Dritte die Geschäftsführung übernehmen. Manchmal kann das aber auch etwas länger dauern – Gogalla war bis zu 483 Tage als Geschäftsführerin eingetragen.
Dieser Report dient als begleitendes Dokument zu meinem Kurztext. Das vorliegende Format könnte ich beispielsweise für interne Zwecke nutzen, um meine Recherche zu dokumentieren und gleichzeitig reproduzierbar machen.
Hiermit möchte ich direkt an einem konkreten Anwendungsbeispiel meine Fähigkeiten zeigen,
Für diesen Bericht bin ich auf die Daten gestoßen, die OffeneRegister.de zur Verfügung stellt. OffeneRegister.de ist ein Projekt des Open Knowledge Foundation Deutschland e.V. mit Daten von OpenCorporates. Der Datensatz basiert auf Abfragen von Handelsregisterbekanntmachungen.de und zum Teil Handelsregister.de.
Zuvor habe ich nicht mit den Daten gearbeitet.
Ein erstes Ziel für diese Recherche könnte sein, dass wir Schlüssel-Akteur:innen des im Datensatz gelisteten Firmen angucken und visualisieren.
Dieses Dokument habe ich mit Quarto erstellt. Es erlaubt, sowohl Markdown-formatierten Text als auch Code in einem Dokument zu vereinen und für verschiedene Einsatzzwecke zu rendern (Dokument, Blog, Website, u. a.). Es wäre auch möglich gewesen, ein PDF als Ausgabe zu wählen, doch bin ich dort in der Darstellung von interaktiven Elementen natürlich limitiert. Deswegen gibt es diese Ausarbeitung als statische html-Seite – gehostet auf der deutschen Alternative zu GitHub: Codeberg.
Die Recherche führe ich mithilfe der Programmiersprache R durch. Die Registerdaten habe ich als SQLite-Datenbank heruntergeladen. Ich kann über die Pakete DBI, RSQLite mit der Datenbank kommunizieren. Ab einem bestimmten Punkt ziehe ich die Daten jeweils in den Arbeitsspeicher und arbeite mit R-Paketen weiter.
Jetzt lade ich erstmal die nötigen Pakete:
library(data.table)
library(DBI)
library(ggplot2)
library(dplyr)
library(DBI)
library(gt)
library(tidyr)
library(textutils)
require(dbplyr)Die Datenbank verfügt über mehrere Tabellen, die ich mir zunächst einmal auflisten lasse. So bekommen wir schnell einen Überblick, was wir erwarten können.
db_path <- here::here("posts", "open-register", "database", "handelsregister.db")
con <- dbConnect(RSQLite::SQLite(), db_path)
dbListTables(con)
## [1] "company" "company_fts" "company_fts_config"
## [4] "company_fts_data" "company_fts_docsize" "company_fts_idx"
## [7] "name" "name_fts" "name_fts_config"
## [10] "name_fts_data" "name_fts_docsize" "name_fts_idx"
## [13] "officer" "officer_fts" "officer_fts_config"
## [16] "officer_fts_data" "officer_fts_docsize" "officer_fts_idx"
## [19] "registrations"Es gibt bei der Benennung offenbar jeweils eine Stammtabelle ohne Namenszusatz und dann ein Schema an Zusätzen (“_fts”, “_fts_config”, “_fts_docsize”, “_fts_idx”, “_fts_data”). Wir arbeiten erstmal mit den Stammtabellen weiter.
Als erstes wäre es schön, wenn wir uns die ersten paar Reihen der Tabellen angucken, um einen Überblick darüber zu bekommen, was uns erwartet.
Beginnen wir mit der Tabelle “Company”. Hier finden wir Spalten zum Firmennamen und -adresse (name, registered_adress), es gibt eine Firmen-Nummer (company_number) und Angaben zum Amtsgericht, das die Eintragung vorgenommen hat (registrar).
tbl(con, "company") |>
colnames()
## [1] "id" "company_number"
## [3] "current_status" "jurisdiction_code"
## [5] "name" "registered_address"
## [7] "retrieved_at" "register_flag_AD"
## [9] "register_flag_CD" "register_flag_DK"
## [11] "register_flag_HD" "register_flag_SI"
## [13] "register_flag_UT" "register_flag_VOE"
## [15] "federal_state" "native_company_number"
## [17] "registered_office" "registrar"
## [19] "register_art" "register_nummer"
## [21] "former_registrar" "register_flag_"
## [23] "register_flag_Note:" "_registerNummerSuffix"
## [25] "register_flag_Status information"Dann finden wir eine Tabelle names name, die den Firmennamen nochmal mit der zugehörigen ID versieht. Hier können wir uns einfach die Spaltennamen anzeigen lassen:
tbl(con, "name") |>
colnames()
## [1] "id" "company_name" "company_id"Deutlich mehr bietet die officer Tabelle. Sie gibt Auskunft über Funktionen von Personen in eingetragenen Firmen/Vereinen. Hier die Spaltennamen:
tbl(con, "officer") |> colnames()
## [1] "id" "name" "position" "start_date" "type"
## [6] "company_id" "city" "firstname" "flag" "lastname"
## [11] "title" "dismissed" "end_date" "maidenname" "reference_no"
tbl(con, "officer") |> head() |>
as_tibble() |>
select(name, position, company_id) |>
gt() |>
tab_header(title="Officer Table")| Officer Table | ||
|---|---|---|
| name | position | company_id |
| Oliver Keunecke | Geschäftsführer | K1101R_HRB150148 |
| Christof Wessels | Geschäftsführer | R1101_HRB81092 |
| Christof Wessels | Geschäftsführer | R1101_HRB81092 |
| Torsten Krausen | Geschäftsführer | H1101_H1101_HRB18423 |
| Hans-Joachim Basch | Prokurist | H1101_H1101_HRB18423 |
| Gerd Bauer | Geschäftsführer | H1101_H1101_HRB18423 |
Hier taucht auch wieder die company_id auf, die in der company-Tabelle aber company_number hieß. Diese Unregelmäßigkeit müssen wir im Hinterkopf behalten, wenn wir Tabellen miteinander in Beziehung setzen möchten.
Als Ergänzung können wir uns hier einmal anschauen, welche verschiedenen Positionen überhaupt erfasst sind:
dbGetQuery(con, "SELECT DISTINCT position FROM officer;")
## position
## 1 Geschäftsführer
## 2 Prokurist
## 3 Liquidator
## 4 Persönlich haftender Gesellschafter
## 5 Vorstand
## 6 InhaberEs sind also nur sechs verschiedene Positionen möglich. Da gibt es also auch keine verschiedenen Schreibweisen oder Schreibfehler, die wir in Gruppen berücksichtigen müssten.
Zu guter letzt finden wir noch die registrations-Tabelle vor mit folgenden Spalten:
tbl(con, "registrations") |> colnames()
## [1] "id" "confidence"
## [3] "data_type" "publication_date"
## [5] "retrieved_at" "source_url"
## [7] "start_date" "start_date_type"
## [9] "subsequent_registration_start_date" "company_id"
## [11] "previous_company_number" "previous_jurisdiction_code"
## [13] "previous_entity_type" "subsequent_company_number"
## [15] "subsequent_jurisdiction_code" "subsequent_entity_type"
## [17] "sample_date" "alternate_company_number"
## [19] "alternate_jurisdiction_code" "alternate_entity_type"
## [21] "previous_registration_end_date"Diese Tabelle zeigt uns Metadaten zur Herkunft der Daten. Das ist wichtig, um die Datenqualität einordnen zu können. Außerdem lernen wir hier, dass wir keine Daten neuer als November 2018 erwarten dürfen.
Als kleines “Hello World”1 möchte ich im Datensatz das Wuppertal Institut heraussuchen. Dazu können wir die große Tabelle der Firmen nach dem Suchbegriff “Wuppertal Institut” filtern.
# Regex matching is not supported in my compiled version of RSQLite,
# so I use the binary search in data.table utilizing grep()
dt <- dbGetQuery(con, "SELECT * FROM company") |> as.data.table()
dt[grepl("Wuppertal Institut", name), .(name,registrar)] |> gt() |> cols_move_to_start(name)| name | registrar |
|---|---|
| Wuppertal Institut für Klima, Umwelt, Energie gGmbH | Wuppertal |
| Die Vereinigung der Freunde des Wuppertal Instituts für Klima, Umwelt, Energie GmbH e.V. | Wuppertal |
Prima! Damit haben wir nachgewiesen, dass tatsächlich nicht nur ein Eintrag für die Wuppertal Institut für Klima, Umwelt, Energie gGmbH existiert, sondern auch ein Eintrag für die Vereinigung der Freunde […] e.V.
Die Officer-Tabelle scheint Personen zu nennen und die Art der Position sowie die zugehörige Firma. Sie nutzt jeweils Zeilen zur Angabe des Starts einer Position und eine eigene Zeile für Änderungen in dieser Rolle, bspw. für Ende der Position als Geschäftsführer:in. Hier müssen wir also später vorsichtig sein, um Personen nicht mehrfach zu gewichten. Eine Lösung könnte sein, dass wir die Reihen mit Positionen einer Person für eine einzelne Firma nur einmal einrechnen.
Um das ganze zunächst ein wenig einzugrenzen, konzentrieren wir uns in dieser Analyse auf Positionen, die als “Geschäftsführer” eingetragen sind.
names_df <- tbl(con, "officer") |>
filter(position == "Geschäftsführer") |>
select(name, company_id) |>
distinct() |>
select(-company_id) |>
count(name, sort=TRUE) |>
as_tibble()
top10_names <- names_df |>
head(10) |>
mutate(`#` = row_number())
top10_names |>
gt() |>
cols_move_to_start(`#`) |>
cols_label() |>
tab_header(title = "Top 10 Personen mit den meisten Eintragungen als Geschäftsführer:in") |>
tab_options(container.height = 500, container.overflow.y = TRUE) |>
as_latex()Die meistgenannten Personen haben wirklich verwirrend viele Eintragungen. Gewiss kann niemand nahezu 5000 Firmen gründen, für die er oder sie aktiv Verantwortung trägt. Die vielen Einträge sind nur als Geschäftsmodell erklärbar, wo durch den Verkauf von sogenannten Vorratsgesellschaften wird gewirtschaftet.
Unser willkürliches Filter von 10 Personen erweist sich bereits als effektiv bzw. angemessen. Denn wir können unter den ersten 10 Personen Unterschiede bereits große Abstände sehen. Das bedeutet, die Personen, welche wir jetzt ausgeklammert haben, sind im Gegenasatz zu den aufgeführten zumindest gemessen an der Anzahl der GF-Nennungen “kleine Fische”. Das heißt natürlich nicht, dass sie grundsätzlich uninteressant sind.
Das ganze können wir uns auch nochmal als Namenswolke anzeigen lassen. Um den Rahmen nicht zu sprengen, zeige ich hier nun die 500 Namen an, die am häufigsten eingetragehn sind.
wordcloud::wordcloud(
words = names_df$name,
freq = names_df$n,
min.freq = 5,
max.words=500,
random.order=FALSE,
rot.per=0.35,
# colors=RColorBrewer::brewer.pal(8, "Dark2"),
scale=c(2,0.1))
Ein Name ist zentral: Mit über 1000 Einträgen Vorsprung war Katja Gogalla Ende 2018 Spitzenreiterin in der Häufigkeit von Geschäftsführerinnenposten. Außerdem ist für mich wirklich überraschend, dass die sechs häufigsten Nennungen Frauennamen sind. Ich bin gespannt, ob wir dafür noch eine Erklärung finden werden.
Nun widmen wir uns also derjenigen Person, welche die Liste der häufigsten Nennungen anführt: Katja Gogalla. Eine kurze Suche führt mich auf die Seite der Firma Blitzstart. Die Blitzstart Holding GmbH und ihre Tochterfirmen verkauft Vorratsgesellschaften. Das bedeutet, dass man mit deren Angebot direkt und mit Anleitung rechtssicher eine Firma beliebiger Rechtsform gründen kann. Katja Gogalla tritt dort als Account Manager auf und scheint seit 2004 dem Unternehmen anzugehören. Blitzstart wirbt heute mit einem Erfahrungsschaftz von über 10.000 abgewickelten Vorratsgesellschaften.
Als erstes möchte ich zeigen, wie viele Einträge pro Monat über die Zeit auf Katja Gogalla fallen – so sehen wir gleichzeitig, welchen Trend die Häufigkeiten haben. Dafür filtere ich die Datenbank nach den gewünschten Kriterien und ziehe die Daten in den Arbeitsspeicher. Dann nutze ich Funktionen für Zeitdaten, um die Daten wie gewünscht zusammenzufassen und zu visualisieren.
entries_gogalla <- dbGetQuery(con, "SELECT name, position, start_date, company_id
FROM officer
WHERE name == 'Katja Gogalla'
AND position == 'Geschäftsführer';") |>
as.data.table()
entries_gogalla[!is.na(start_date), .(.SD, date = lubridate::ym(gsub('.{3}$', '', start_date)))][, .N, by=date] |>
ggplot(aes(x=date, y=N)) +
geom_point() +
geom_smooth(formula = y ~ x, method = "lm") +
scale_x_date(date_breaks = "1 year", date_labels = "%Y") +
labs(
x = "Jahr",
y = "Anzahl Einträge",
title = "Katja Gogalla: Einträge pro Monat und Trend"
) +
theme_minimal()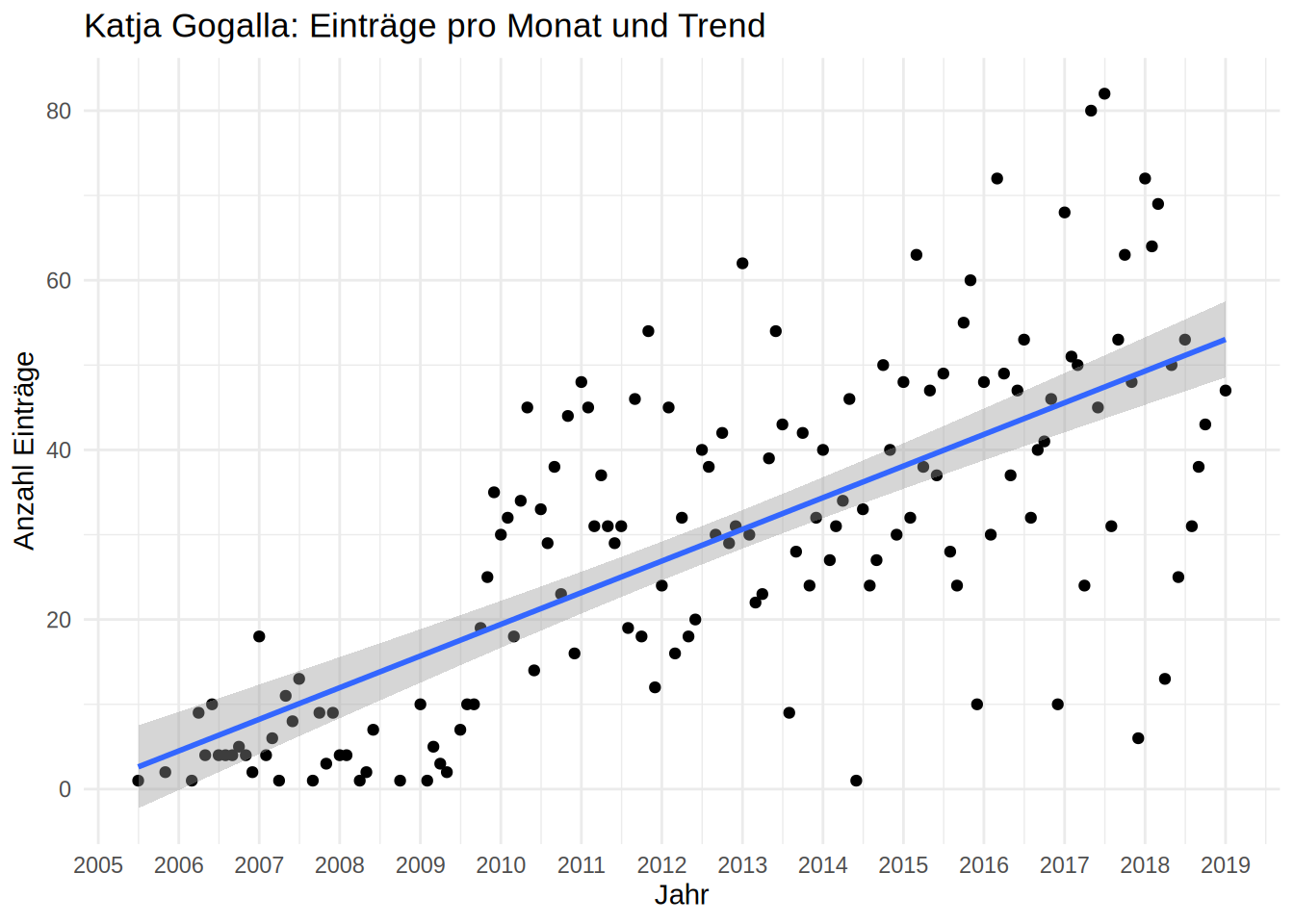
Unser Diagramm zeigt, dass Gogalla zu Spitzenzeiten im Jahr 2017 über 80 Mal im Monat als Geschäftsführerin eingetragen wurde. Zudem können wir der Trendlinie ablesen, dass Frau Gogalla die monatliche Anzahl der Einträge pro 5 Jahre um ca. 20 erhöhen konnte. Spaßeshalber können wir auch berechnen, wieviele Firmeneinträge Frau Gogalla als besten Tageserfolg geschafft hat.
entries_gogalla[!is.na(start_date), .(firms_per_day=.N, date=as.Date(start_date)), by=as.Date(start_date)][
order(-firms_per_day), .(firms_per_day, date)] |>
unique() |>
head(1) # weil wir die Liste mit order() schon geordnet hatten, zeigt dieser Befehl direkt den besten Tag an
## firms_per_day date
## <int> <Date>
## 1: 34 2016-01-19Als Rekord können wir die absurde Zahl von 34 Einträgen am 19.1.2016 ermitteln. Gefühlt kann niemand 34 Firmen gleichzeitig gründen und im engeren Sinne leiten.
Interessant ist auch der Blick darauf, wie lange Katja Gogalla jeweils GF der Firmen ist. Werden Firmen schnell wieder umgeschrieben oder bleibt Gogalla längere Zeit im Amt? Um das zu Beantworten bauen wir uns zunächst eine neue Spalte duration. Das geht nur mit vollständigen Datensätzen, deswegen filtern wir hier sogenannte NA Werte heraus. Dann sind einfache Statistiken (Mittelwert, Minimum, Maximum, Standardabweichung) schon aussagekräftig:
times_gogalla <- dbGetQuery(con, "SELECT name, position, start_date, end_date, company_id FROM officer WHERE name == 'Katja Gogalla' AND position == 'Geschäftsführer';") |>
as.data.table()
times_gogalla[!is.na(start_date) & !is.na(end_date),.(company_id, start = lubridate::ymd(start_date), end=lubridate::ymd(end_date))][
, .(duration = end - start)][
, .(Mean = mean(duration), Median = median(duration), Max = max(duration), Min = min(duration), SD = sd(duration))
] |>
melt() |>
gt() |>
cols_label(
variable = "", value = "Dauer"
) |>
fmt_duration(columns = everything(), input_units = "days", output_units = "days")| Dauer | |
|---|---|
| Mean | 108d |
| Median | 84d |
| Max | 483d |
| Min | 8d |
| SD | 79d |
Die Firmen bleiben also immer einige Zeit unter der Führung der eingesetzten GF bis sie übertragen werden. Ein exakteres Bild bekommen wir durch Betrachtung der Verteilung der Dauern.
times_gogalla[!is.na(start_date) & !is.na(end_date),.(company_id, start = lubridate::ymd(start_date), end=lubridate::ymd(end_date))][
, .(duration = end - start)] |>
ggplot(aes(x=duration)) +
geom_histogram(binwidth = 5) +
geom_vline(aes(xintercept = mean(duration)),
linetype = "dashed", size = 1) +
labs(
x = "Dauer (Tage)",
y = "Häufigkeit",
title = "Katja Gogalla: Verteilung der GF-Zeiten (Dauer)"
) +
theme_minimal()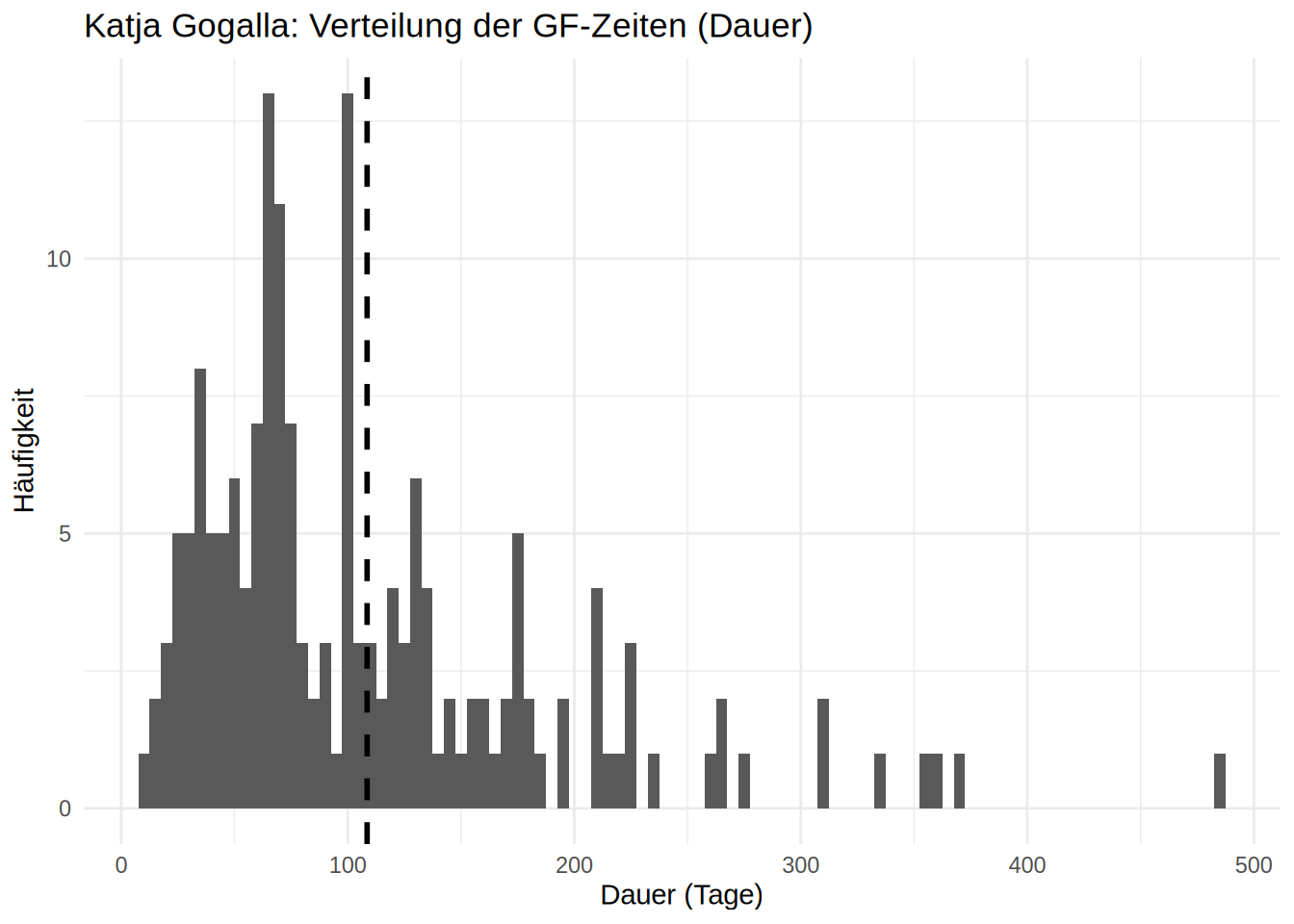
Das Histogramm ist hier tatsächlich hilfreich! Wir sehen, dass der Mittelwert ein Bild repräsentiert, das durch die hohen Ausreißer-Werte verzerrt wurde. So können wir dem Histogramm ablesen, dass Gogalla gleichhäufig um die 100 Tage und ca. 60 Tage Geschäftsführerin ist. Gleichzeitig gibt es eine Ballung bei ca. 30 Tagen. Der Median ist 84 Tage. Das bedeutet, dass 50% der Firmen schneller als 84 Tage umgeschrieben werden.
Jetzt möchte ich noch einen Einblick in die Firmen gewinnen, die über Katja Gogalla eingetragen wurden. Weil es so viele sind, zeige ich 10 zufällige Einträge an:
entries_company <- dbGetQuery(con, "SELECT name, company_number, registered_address
FROM company;") |>
as.data.table()
# set keys for faster joins
setkey(entries_company, "company_number")
setkey(entries_gogalla, "company_id")
relevant_entries <- entries_gogalla[!is.na(company_id)][
# inner join on company id
entries_company,on=c(company_id="company_number"), nomatch=0]
# delete object to save some memory
rm(entries_company)
set.seed(42) # for reproducability of sampling
unique(relevant_entries[ ,.(Firmenname = i.name)])[sample(.N,10)] |>
gt()| Firmenname |
|---|
| Sana Vitalis GmbH |
| IAG Holding GmbH |
| AMIDES GmbH |
| Vestabilio Holding GmbH |
| Zebra GP GmbH |
| clearando GmbH |
| Springs and Foam GmbH |
| Dritte Laura Beteiligungsgesellschaft mbH |
| S.L.V. Elektronik Holding GmbH |
| Alent Germany GmbH |
Aus meiner Sicht gibt es hier keinen inhaltlichen Schwerpunkt. Die Firmen scheinen auf diverese Branchen zu fallen.
Zu guter letzt können wir noch die registrierten Adressen nutzen, um zu sehen, für welche Gesellschaftsstandorte Katja Gogalla als Geschäftsführerin auftrat. Mit einem kommerziellen API-Key kann man bei bestimmten Anbietern schnell auch mit hoher Bandbreite Geocoding betreiben, also Adressen in Koordinaten übersetzen. Weil mir das hier nicht zur Verfügung steht wähle ich 100 Einträge zufällig aus. Das dauert dann via Open Street Maps ca. 100 Sekunden.
Die interaktive Karte steht wegen Paketinkompatibilitäten aktuell nicht zur Verfügung.
set.seed(42) # for reproducability of sampling
N_SAMPLES <- 100
df <- tidygeocoder::geocode(relevant_entries |>
sample_n(N_SAMPLES), address = registered_address, method = "osm")
mymap <- sf::st_as_sf(df |>
filter(!is.na(lat) & !is.na(long)), coords = c("long", "lat"), crs = 4326)
mapview::mapview(mymap)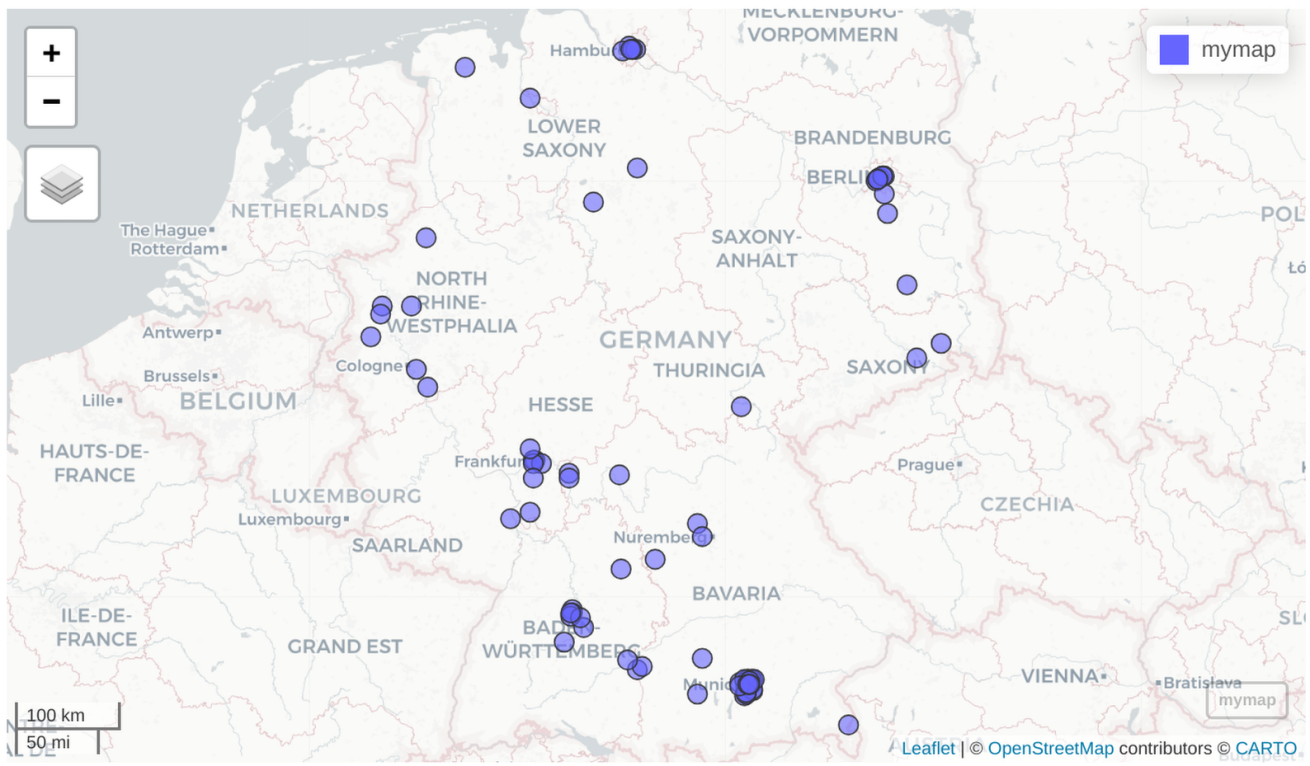
Wir sehen eine breite Verteilung von Einträgen auf der Karte. Während es eine Ballung um Berlin herum gibt, liegen die meisten Firmeneinträge allerdings im Süden und Westen Deutschlands. Ballungen sind in diesem Sample um München, Stuttgart, Frankfurt und Hamburg zu sehen.
In diesem Dokument zeige ich, wie ich mich systematisch einem neuen Datensatz nähere. Mithilfe der Zählung von Häufigkeiten sowie einfacher, statistischer Funktionen erhalte ich Einblicke zu Sachverhalten und wichtigen Zusammenhängen. So kann ich mit wenig Aufwand Muster in den Daten erkennen.
Durch meine Analyse der Häufigkeiten in den Geschäftsführer:innen-Einträgen konnte ich eine zentrale Person des deutschen Marktes für Vorratsgellschaften identifizieren. Mithilfe von Statistiken und durch Arbeit mit den Zeitdaten konnte ich die Charakteristiken der Arbeit der Marktführerin herausarbeiten.
In dieser Recherche zeige ich weitehrin, wie ich diese Datenerkenntnisse schlüssig mit externen Informationen verbinden kann. Ich zeige verschiedene Tools aus meinem Werkzeugkasten, die mir helfen einzelnen Fragestellungen nachzugehen und Daten aus verschiedenen Perspektiven zu betrachten. Mit dieser strukturierten Arbeitsweise stelle ich sicher, dass meine Schritte auch für Mitarbeitende gut nachvollziehbar sind und auch von anderen wiederholt werden können.
So nennen Programmierende, ein einfaches Programm, das in einer Programmiersprache den Text “Hello, World!” ausgibt. Der Name kann – etwas weiter gefasst – für Minimalbeispiele genutzt werden, die zeigen, dass eine (neue) technische Kette funktioniert.↩︎